

논문 요약
✅ Problem
- •기존 임베딩 복원 방법(vec2text)은 각 인코더마다 별도의 모델을 학습해야 하고, 수백만 개 쿼리와 고성능 GPU가 필요한 비현실적 접근임.
- •또한, 노이즈 방어 기법이 적용된 임베딩에는 복원 성능이 급격히 떨어짐.
- •따라서, 훈련 없이 바로 사용 가능하고, 쿼리 효율적인 보편적 임베딩 복원 방법이 필요함.
✅ Main Idea / Solution
- •ZSinvert: 쿼리 효율적이고, 모든 인코더에 **제로샷(zero-shot)**으로 작동하는 보편적인 임베딩 복원 방법 제안.
- •핵심 전략: Adversarial Decoding + Multi-stage Guided Generation
- •다양한 인코더에도 제로샷으로 적용 가능
✅ Result
- •기존 방식(vec2text)과 달리, 인코더별 모델 학습 없이도 의미 복원이 가능하며, 오프라인에서 학습된 보편적인 보정 모델을 통해 결과 품질을 개선함.
- •완벽한 단어 복원이 아니더라도, 임베딩이 담고 있는 핵심 의미 정보는 효과적으로 복원함.
- •임베딩에 가우시안 노이즈가 추가되더라도 (검색 성능이 유지되는 범위 내에서는) 복원 성능이 유지됨 → 방어 기법에 대한 강건성 보유
Abstract
임베딩 역변환(Embedding inversion) 은 주어진 임베딩과 인코더에 대한 블랙박스 접근만으로 원래 텍스트를 복원하는 문제로, 자연어처리(NLP)에서는 임베딩이 의미를 얼마나 잘 보존하는지 평가하는 데, 보안 측면에서는 임베딩을 통해 정보가 얼마나 유출되는지를 판단하는 데 중요합니다.
하지만 기존의 최신 기법들(예: vec2text)은 높은 정확도를 가지지만, 각 임베딩마다 별도 모델을 학습해야 하며, 많은 수의 인코더 쿼리가 필요하다는 단점이 있습니다. 이에 본 논문에서는 ZSinvert라는 새로운 제로샷(Zero-shot) 임베딩 복원 기법을 제안합니다. adversarial decoding 기법을 기반으로 하며, 빠르고 쿼리 효율적이고, 별도 학습 없이 모든 임베딩에 적용 가능합니다. 실험을 통해 다양한 임베딩에서 ZSinvert가 원문 텍스트의 핵심 의미 정보를 성공적으로 복원함을 입증했습니다.
1. Introduction
기존 문제
- •기존 SOTA Embedding Inversion 방식인 vec2text는 임베딩마다 별도 모델을 학습해야 함
- •이 모델을 학습하기 위해 5백만 개의 문장-임베딩 쌍이 필요함(모델에 5백만 번의 쿼리를 보낸다는 의미)
- •학습을 위해서 고성능 GPU 4개를 2일 동안 돌려야 함
- •게다가, 특정 시스템에서는 임베딩이 외부에 노출되더라도 안전하도록 가우시안 노이즈를 추가하는 경우가 있는데, vec2text는 이런 노이즈 방어가 적용된 임베딩에는 복원 성능이 많이 떨어지게 됨
해결 방법
- •적대적 디코딩(adversarial decoding) 기법을 기반으로 한 임베딩 복원 방법인 ZSinvert를 사용
- •vec2text와 달리, ZSinvert는 범용적 : 임베딩마다 별도의 복원 모델을 따로 학습하지 않고 동일한 알고리즘을 모든 임베딩에 적용 가능
- •ZSinvert는 생성된 텍스트의 품질을 향상시키기 위해 보정 모델(correction model)을 필요로 하지만, 이 모델은 한 번만 학습하면 되고, 특정 임베딩에 종속되지 않음
- •따라서 ZSinvert는 기존의 임베딩은 물론, 앞으로 등장할 임베딩에도 제로샷 방식으로 적용할 수 있음
- •ZSinvert는 vec2text에 비해 인코더에 훨씬 적은 수의 쿼리만 필요하며, vec2text와 달리 임베딩에 σ = 0.01 수준의 노이즈가 추가되어도 여전히 효과적으로 작동
- •ZSinvert가 생성한 복원 문장은 vec2text만큼 정밀하지는 않지만, 원래 문장과 의미적으로는 매우 유사하며, F1 점수 50 이상, 코사인 유사도 90 이상을 달성함
보안 이슈 발생 가능
- •ZSinvert는 간단하고 제로샷 방식으로 작동하기 때문에, 기술 수준이 낮은 공격자(해커)조차도 사용 가능
- •보안적인 관점에서, 기밀 문서나 민감한 문서의 임베딩을 제3자 서비스와 공유하는 것은 원문 문서 자체를 공유하는 것과 다름없음
- •임베딩만으로도 민감한 정보가 유출될 수 있기 때문에, Pinecone, Weaviate와 같은 벡터DB에 마음 놓고 임베딩을 맡기면 안 됨
Threat model
가정 상황
- •공격자는 임베딩은 가지고 있지만, 그 임베딩이 어떤 텍스트로부터 생성됐는지()는 모름
- •하지만 인코더 는 사용할 수 있음 → 임의의 문장을 넣고 어떤 임베딩이 나오는지 확인 가능
- •공격자는 원문은 모르지만, 해당 임베딩과 (노이즈가 없는 임베딩을 생성하는 원래) 인코더에 쿼리할 수 있는 상황에서 복원을 시도할 수 있음
- •이는 오픈소스로 공개된 임베딩�의 경우 현실적인 가정임
공격자의 목표 : 원래 입력 에 가까운 텍스트 시퀀스 를 복원하거나, 최소한 로부터 최대한 많은 정보를 담고 있는 문장을 생성하는 것
특히 벡터 데이터베이스나 검색 시스템이 침해되어 그 안�에 저장된 임베딩이 공격자에게 노출되는 상황에서 발생하는 위협상황에 주목한다. 이러한 시나리오에서 공격자의 목표는, 문서를 토큰 수준에서 정밀하게 복원하는 것이 아니라, 그 문서에 담긴 일부 기밀 정보를 알아내는 것이다. 이는 완벽한 복원은 아니나 훨씬 더 현실적인 위협이 될 수 있다.
또한 우리는 임베딩 복원을 방해하기 위해, 임베딩에 가우시안 분포로부터의 무작위 노이즈를 더하는 방어 기법을 적용한 시나리오도 고려한다. 이 경우, 대상 임베딩 는 형태가 되며, 여기서 σ는 랜덤 노이즈이다.
임베딩 복원(embedding inversion) 작업은 다음과 같이 정의된다:
주어진 텍스트 임베딩 과, 이 임베딩을 생성한 사전 학습된 인코더 에 대한 쿼리 접근이 가능할 때, 가 과 최대한 유사하도록 하는 텍스트 를 생성하는 것이 목표이다.
수학적으로는 다음과 같은 최적화 문제로 표�현된다:
- •: 복원하려는 대상 임베딩 (이미 알고 있음)
- • : 해당 임베딩을 만든 인코더 (공격자가 쿼리 가능하다고 가정)
- • : 우리가 찾아야 할 복원 텍스트
- • : 코사인 유사도 등의 임베딩 유사도 함수
- • : 유사도가 최대가 되도록 하는 최적의 텍스트
여기서 는 (길이 제한이 있는) 가능한 모든 텍스트 시퀀스의 공간이며, 은 코사인 유사도 함수.
가능한 모든 텍스트 공간 X에 대해 모든 문장을 하나하나 넣어보는 brute-force 방식으로 탐색하는 것은, 가능한 조합의 수가 너무 많기 때문에 계산적으로 불가능. 다행히도 자연어 시퀀스(문장)는 강한 통계적 규칙성을 가지고 있음(어떤 단어 다음에 어떤 단어가 나올 확률이 높다는 뜻). 이 성질 덕분에 우리는 전체 탐색 대신, 가능성이 높은 문장만 똑똑하게 골라서 시도 → 즉, LLM + beam search + 유사도 최적화 방식이 가능해지는 이유
어떤 Prefix(문장 앞부분)가 주어지면, 다음 토큰에 대한 확률 분포는 일반적으로 전체 어휘 중 일부에 집중됨. 이런 특성 덕분에 LLM은 매우 큰 문장 공간에서 효율적으로 탐색할 수 있음. 즉, 실질적인 탐색 공간이 전체 가능한 시퀀스 공간 보다 훨씬 작다는 것.
게다가 텍스트 인코더는 의미적으로 유사한 문장들이 임베딩 공간에서 서로 가까운 위치에 매핑되도록 학습됨. 따서 목표 임베딩 을 기준으로, 그와 유사한 임베딩을 만들어낼 수 있는 문장을 효율적으로 찾아낼 수 있음.
적대적 디코딩(adversarial decoding)을 기반으로, LLM을 활용해 목표 텍스트를 탐색하는 빔 서치 기반 전략을 제안. 일반적으로 LLM은 문장의 유창성을 목표로 해, 전체 문장의 로그 확률 를 최대화하는 반면, 본 논문의 목표는 임베딩 복원 → 단순한 문장의 유창성보다는 과의 의미적 일치(semantic fidelity)를 더 우선시.
Adversarial Decoding 작동방식
- •
1. 초기 프롬프트 P 시작
- •예: "tell me a story" 같은 일반적인 문장 시작
- •
2. 빔 서치 진행 (beam size = b)
- •여러 개의 문장 후보(부분 시퀀스) b개를 동시에 관리함
- •각 단계에서 확장될 수 있는 가능성 높은 다음 토큰 k개를 LLM이 제안함
- •
3. 후보 문장 확장
- •각 후보 문장 에 대해 top-k 토큰을 이어붙여 새로운 시퀀스를 만듦 →
- •
4. 확률 기반이 아닌 임베딩 기반 점수
- •일반 LLM은 "확률이 높은 문장"을 선택하지만
- •ZSinvert는 그 문장의 임베딩이 과 얼마나 유사한지(코사인 유사도)를 기준으로 점수를 매김
- •아래 식에서 가장 높은 점수를 받은 상위 b 개의 시퀀스를 다음 단게로 가져간다.
즉, ZSinvert(Zero-Shot Inversion) 는 빈 문자열로 beam search를 시작하면 처음에 탐색할 문장 후보가 너무 많기 때문에, multi-stage framework를 사용해 탐색 결과를 점차 refine 해나가는 방식을 사용.
그래서 ZSinvert는 다음과 같이 단계적으로 접근:
- •
Stage 1 – Initial Seed Generation: LLM으로 대충 유사한 문장 하나 뽑기
- •목표 : 목표 텍스트가 포함될 수 있는 의미 공간의 다양한 영역 탐색
- •Initial Prompt(시드 문장)로 "tell me a story" 를 사용함. (왜? LLM이 다양한 문장을 자율적으로 생성하도록 유도하는 중립적이고 풍부한 프롬프트라고 함)
- •
Stage 2 – Refinement: 더 비슷한 문장으로 다듬기
- •시드 문장으로 LLM 에게 의미가 비슷한 문장을 생성하도록 함
- •prompt : write a sentence similar to : <시드 문장>
- •그리고 만들어진 각 에 대해, 코사인 유사도 기반의 빔 서치를 수행
- •최종 단계에서는 유사도가 가장 높은 문장을 b개 선택
- •
Stage 3 – Correction: 오프라인 모델로 문장을 매끄럽게 정리하기
- •보정 모델은 하나 또는 여러 개의 복원 후보 문장을 입력으로 받아 정정함
- •Algorithm 2에서는 이 과정을 반복적으로 사용
- •이 알고리즘은 2단계와 3단계를 여러 번 반복하며, 각 반복에서 나온 2단계 결과들을 리스트로 모음
- •보정 모델은 이 리스트를 바탕으로 최종 출력을 생성 → 그 결과는 다음 반복의 시드(seed)로 다시 2단계에 사용
- •는 복원 과정에서 목표 임베딩 e_target이나 인코더 E에 접근할 필요가 없음
- •이 모델은 공격자의 로컬 인코더 을 사용해 생성한 합성 데이터로 사전에 학습될 수 있으며, 이는 E와는 �다른 인코더일 수도 있음
- •학습 데이터는 다음과 같은 형태로 구성:
- •(원본 문장 , )
- •→ 여기서 는 을 넣고 Stage 1과 2를 거쳐 생성된 후보 복원 문장들
- •이러한 오프라인 학습과 인코더 비종속적인 보정 방식 덕분에,
- •는 어떤 인코더에도 제로샷으로 적용 가능, 보정 모델이 학습될 당시 존재하지 않았던 인코더에도 사용 가능, 복원 과정에서 추가적인 인코더 쿼리가 필요 없기 때문에 효율적
- •이는 decoding과 correction ��과정에서 인코더에 반복적으로 접근해야 하는 기존 vec2text 방식과 비교되는 큰 장점
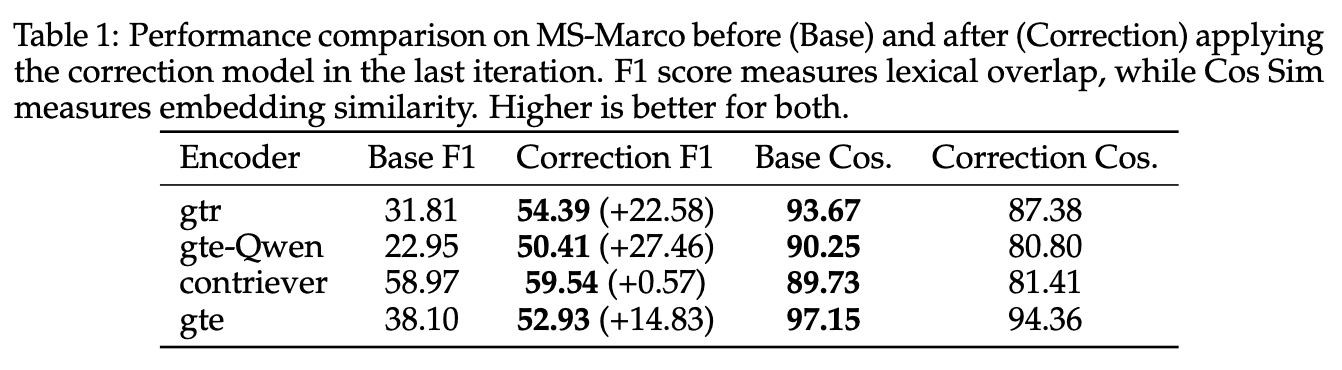
평가 및 결과
다양한 임베딩 인코더(encoder), 데이터셋(dataset), 방어 기법(defense)에 대해 ZSinvert의 성능을 평가함
사용된 임베딩 인코더
GTR(T5기반), Contriever(BERT기반), GTE(BERT기반), GTE-Qwen2-1.5B-instruct(Qwen기반)
사용된 데이터셋
- •MS MARCO v2.1: 100만 개의 쿼리-문서 데이터셋 (검색/질문응답용 벤치마크)
- •Enron 이메일: 실제 기업 이메일 → 기밀 정보 복원 테스트에 적합
- •기본적으로 문서의 처음 32 토큰만 사용 (길이 실험 제외)
Correction Model()의 학습방식
- •사용한 LLM : Qwen2.5-3B-Instruct
- •MS-Marco 문서 400개를 선택 후, 각 문서를 Contriever 인코더로 임베딩
- •각 임베딩에 대해 Stage 2까지 실행 → 복원 후보 문장 5개 생성
- •이 복원 후보들이 입력, 원문 문장이 정답 (supervised fine-tuning)
- •프롬프트 템플릿: Given the following texts sorted by relevance to the target, predict the target: Texts: <inversions> Target: <target>
- •후보 복원 문장 5개를 보여주고 가장 잘 맞는 원문을 맞추도록 훈련
- •학습 objective: causal language modeling (CLM) 방식 사용, 다만 loss는 정답(target) 토큰��에만 계산
- •→ 즉, 모델이 여러 후보 중에서 정답을 “선택”할 수 있도록 유도
추가 실험
- •텍스트 길이 변화에 따른 보정 모델 성능
- •기본 학습은 32토큰 문서 기준
- •추가로 다양한 길이의 문서에서도 보정 모델을 따로 학습하여 길이 변화에 대한 일반화 성능도 측정함
평가 지표
- •Cosine Similarity : 원문 텍스트 임베딩과 복원된 임베딩 간의 코사인 유사도
- •F1 Score : 토큰 수준의 정확도 평가, BLEU는 기계 번역용으로 일반적으로 사용되나, 복원 문제에서는 단어 순서보다 의미 복원이 더 중요하므로 F1을 사용
- •LLM Judge Leakage Score : Enron 이메일 복원 시 민감 정보가 노출되었는지를 정성적으로 평가
하이퍼파라미터
- •Beam size = 30, Top-k 샘플링 = 30, 반복 횟수 = MS MARCO: 9회 / Enron: 3회
계산 리소스 및 시간
- •NVIDIA A40 GPU (1대)
- •1회 반복 소요 시간: 10초
- •전체 복원 시간:
- •MS MARCO 문서 1개: 9회 반복 → 약 90초
- •Enron 이메일 1개: 3회 반복 → 약 30초
- •Correction model 학습: 약 10분 소요


단어 복원이 완벽하진 않지만, Enron 이메일처럼 기밀 문서의 핵심 의미와 민감 정보가 유출됨을 보여줌. GPT-4가 평가한 정보 누출률은 최대 92%로 평가됨.
결론
ZSinvert는 보편적이고 훈련이 필요 없는 임베딩 복원 방법으로, 의미 정보 복원에 강력하며 다양한 인코더에 적용 가능하지만, 여전히 인코더 쿼리에 의존한다는 한계가 있음. 하지만 다음 논문(2025.05)에서는 인코더 없이도 임베딩 복원이 가능하다는 것을 보여주는



